








What is Azure Data Factory?
In the world of big data, raw, unorganized data is often stored in relational, non-relational, and other storage systems. However, on its own, raw data doesn’t have the proper context or meaning to provide meaningful insights to analysts, data scientists, or business decision makers.
Azure Data Factory is the platform that solves such data scenarios. It is the “cloud-based ETL and data integration service that allows you to create data-driven workflows for orchestrating data movement and transforming data at scale”. Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) that can ingest data from disparate data stores. You can build complex ETL processes that transform data visually with data flows or by using compute services such as Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database.
Working
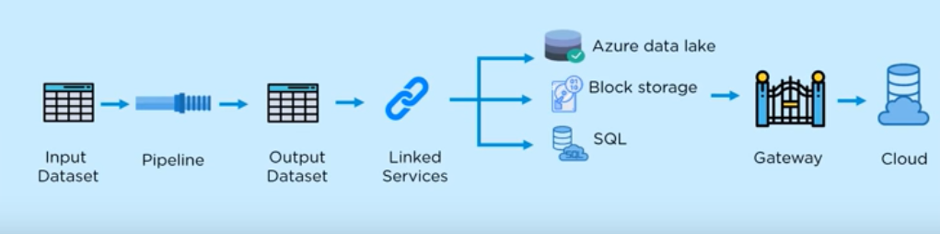
Input Dataset – Represents the collection of data which presents in your data store.
Pipeline – Pipeline perform an operation on the data transforms it which could be anything from just data movement or some data transformation. Data Transformation is possible by USQL, stored procedure and Hive.
Output Dataset – It will contain data in structured format.
Linked Services – Here we mention the source and destination of the data. Generally, our source and destination are Azure Data Lake, Block storage, SQL.
Gateway – Connects your on-premise data ta to cloud. It is installed on the on-premises data system of client, which then connects to Azure Data.
Cloud – The data can be analysed and visualized using different analytical framework like R, Spark, Hadoop.
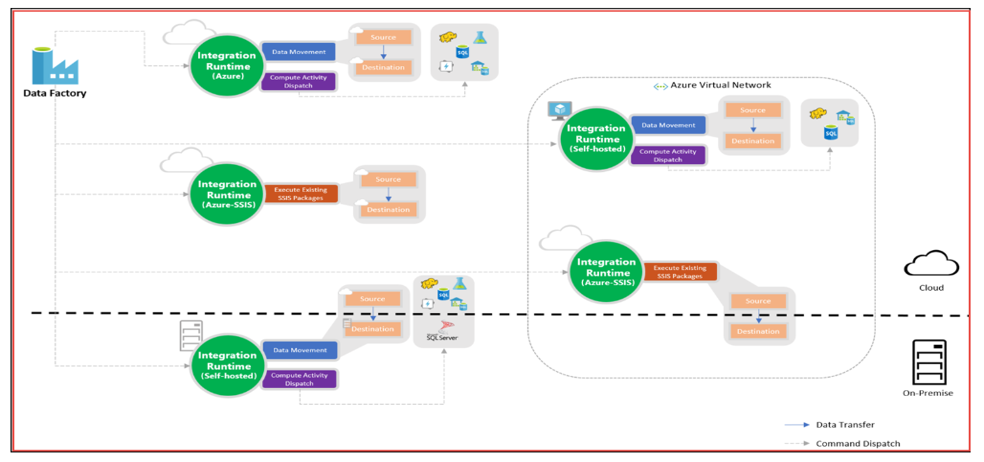
Integration Runtime
An integration runtime provides the bridge between the activity and linked Services. An activity defines the action to be performed. A linked service defines a target data store or a compute service. This way, the activity can be performed in the region closest possible to the target data store or compute service in the most performant way while meeting security and compliance needs.
The Integration Runtime (IR) is the compute infrastructure used by Azure Data Factory to provide the following data integration capabilities across different network environments:
- Data Flow: Execute a Data Flow in managed Azure compute environment.
- Data movement: Copy data across data stores in public network and data stores in private network (on-premises or virtual private network). It provides support for built-in connectors, format conversion, column mapping, and performant and scalable data transfer.
- Activity dispatch: Dispatch and monitor transformation activities running on a variety of compute services such as Azure Databricks, Azure HDInsight, Azure Machine Learning, Azure SQL Database, SQL Server, and more.
- SSIS package execution: Natively execute SQL Server Integration Services (SSIS) packages in a managed Azure compute environment.
Type of Integration Runtime
- Azure
- Self-hosted
- Azure SSIS
The following table describes the capabilities and network support for each of the integration runtime types:
| IR Type | Public Network | Private Network |
| Azure | Data Flow, Data Movement, Activity Dispatch |
NA |
| Self-Hosted | Data Movement, Activity Dispatch |
Data Movement, Activity Dispatch |
| Azure-SSIS | SSIS package execution | SSIS package execution |
Azure Data Factory vs SSIS. To be continued…
Please find the PART 2 :
https://www.ifi.tech/?p=5198&preview=true



