












Author – Moulshree Suhas, Cloud Engineer
Azure Databricks is a fast and collaborative Apache Spark based analytics platform on Azure. The interactive workspaces and streamlines workflows enable data scientists, data engineers and business analyst to work on big data with ease to extract, transform and load data. Integration with variety of data sources and services like Azure SQL data warehouse, Azure Cosmos DB, Azure Data lake, Azure blob storage, Event hub and Power BI. Azure Databricks provides a secure and scalable environment with Azure Active directory integration, role-based access, machine learning capabilities, reduced cost combined with fully managed cloud platform.
This document will help create an end to end Databricks solution to load, prepare and store data.
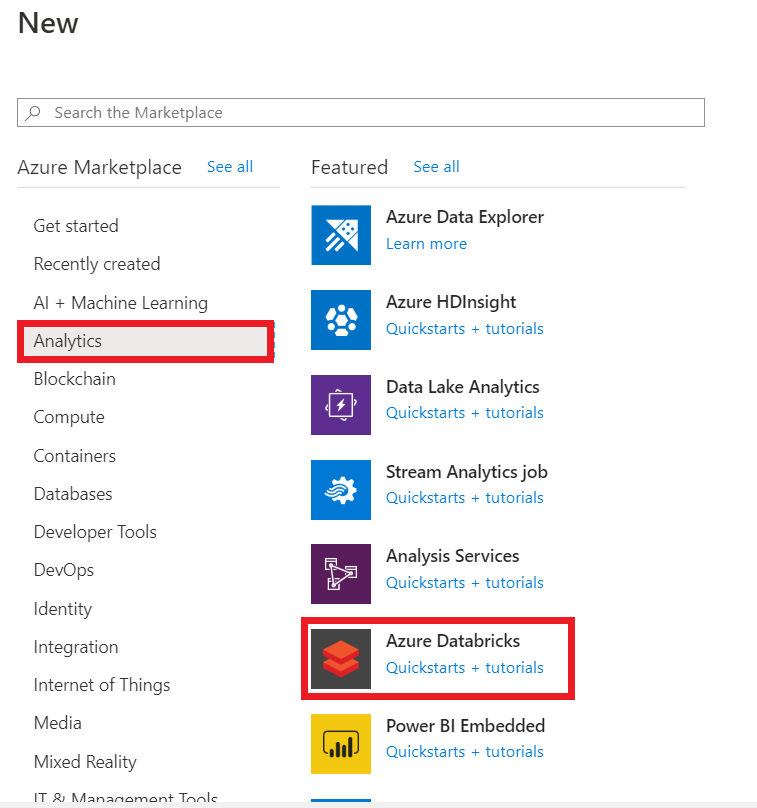
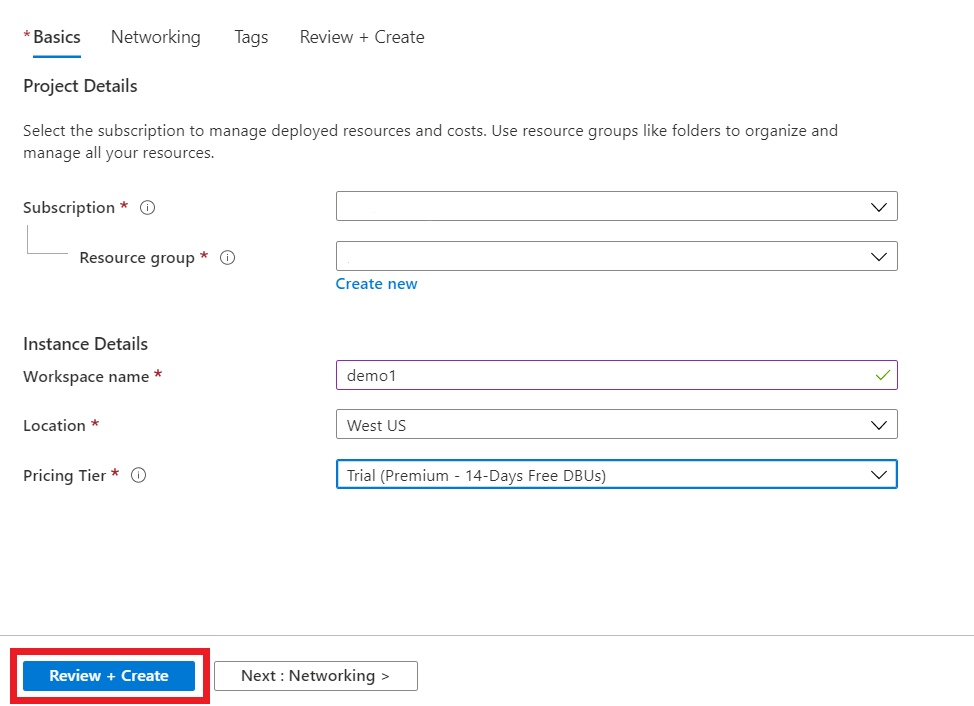
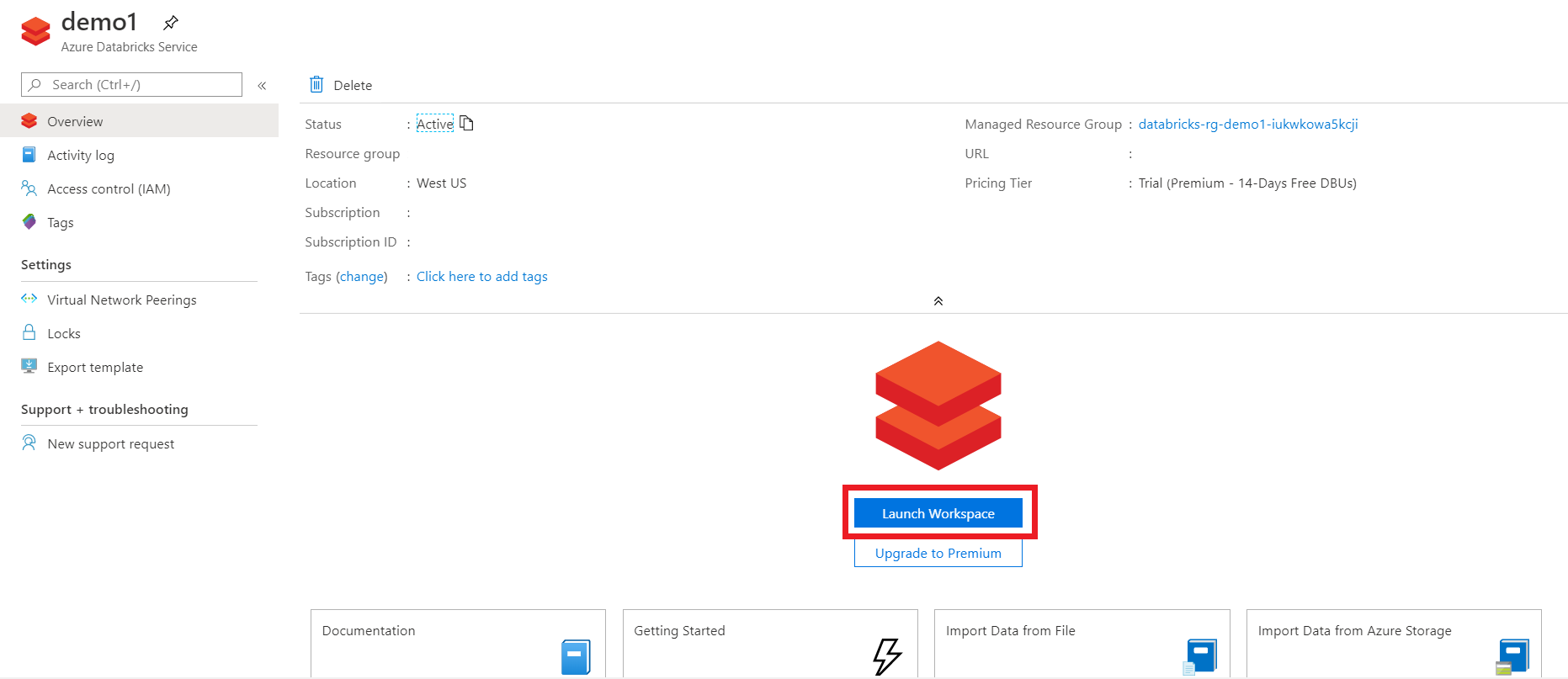
STEP 1: Create Azure Databricks
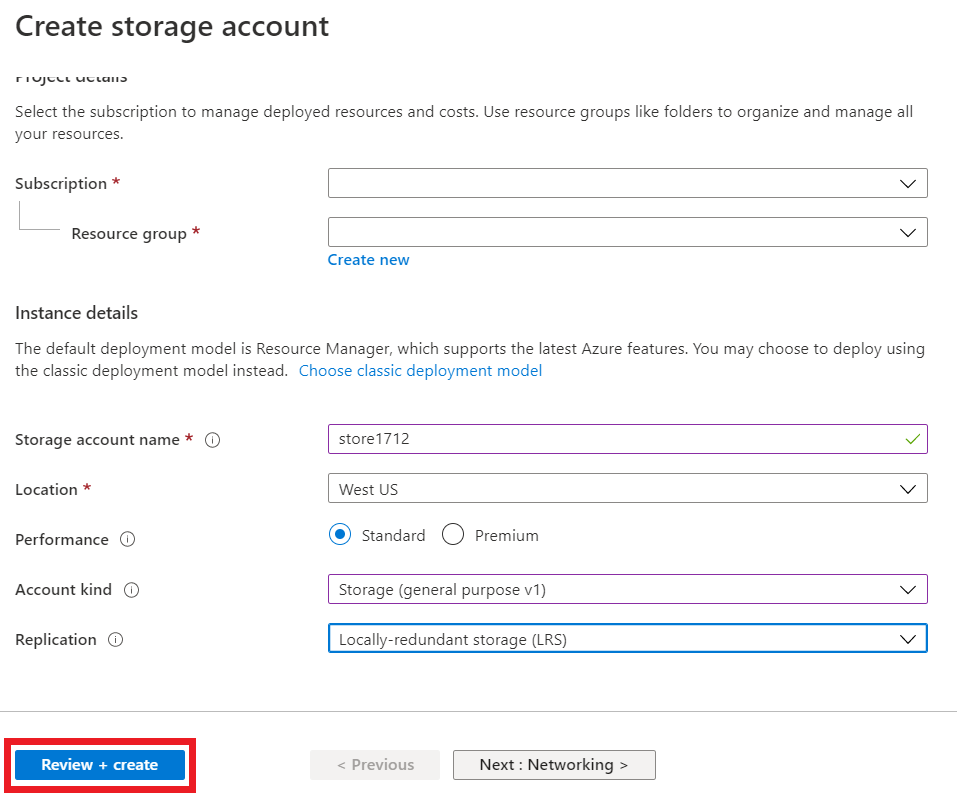
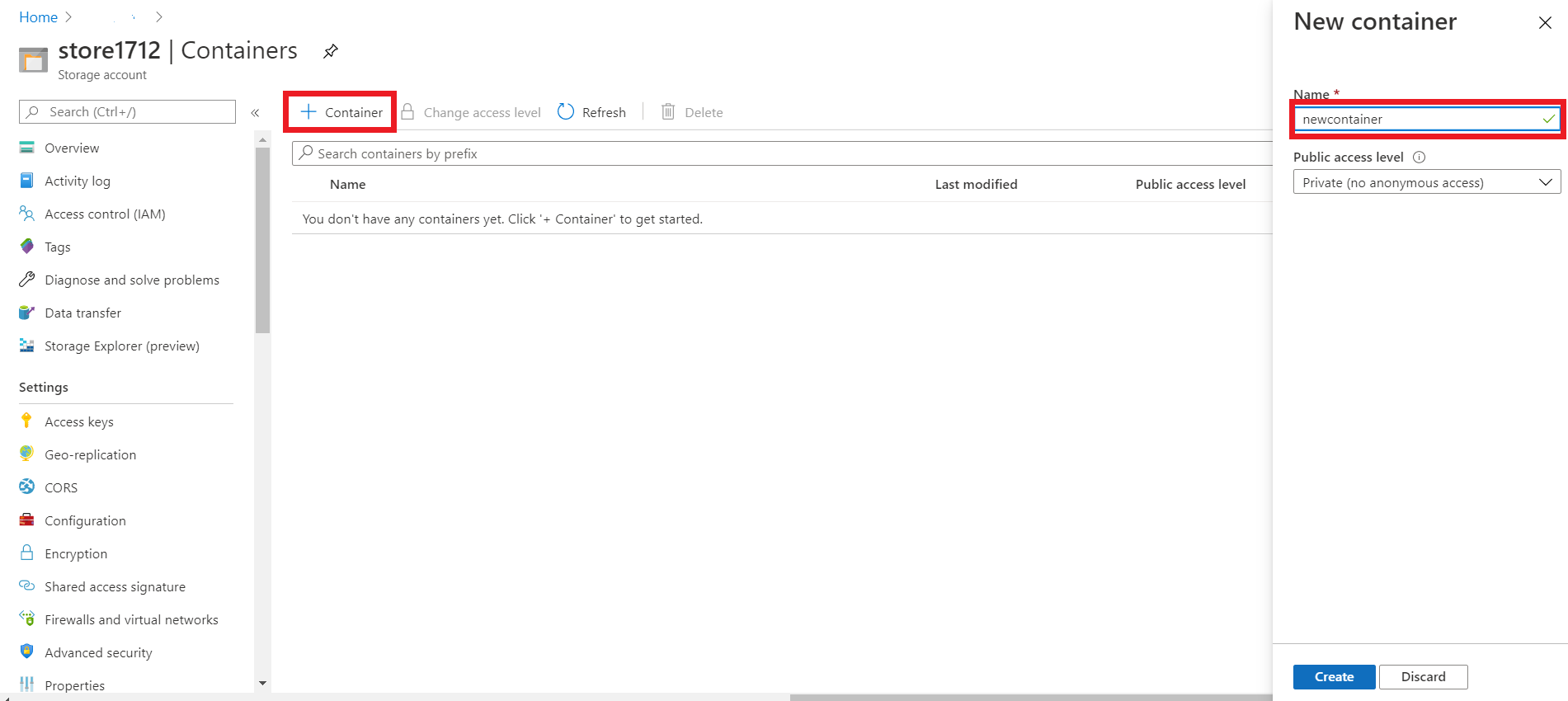
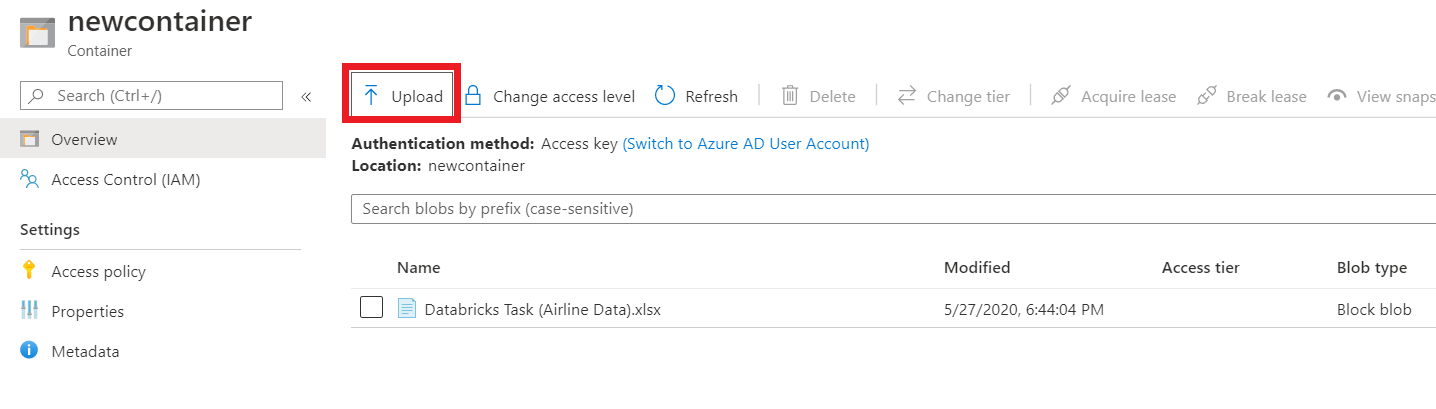
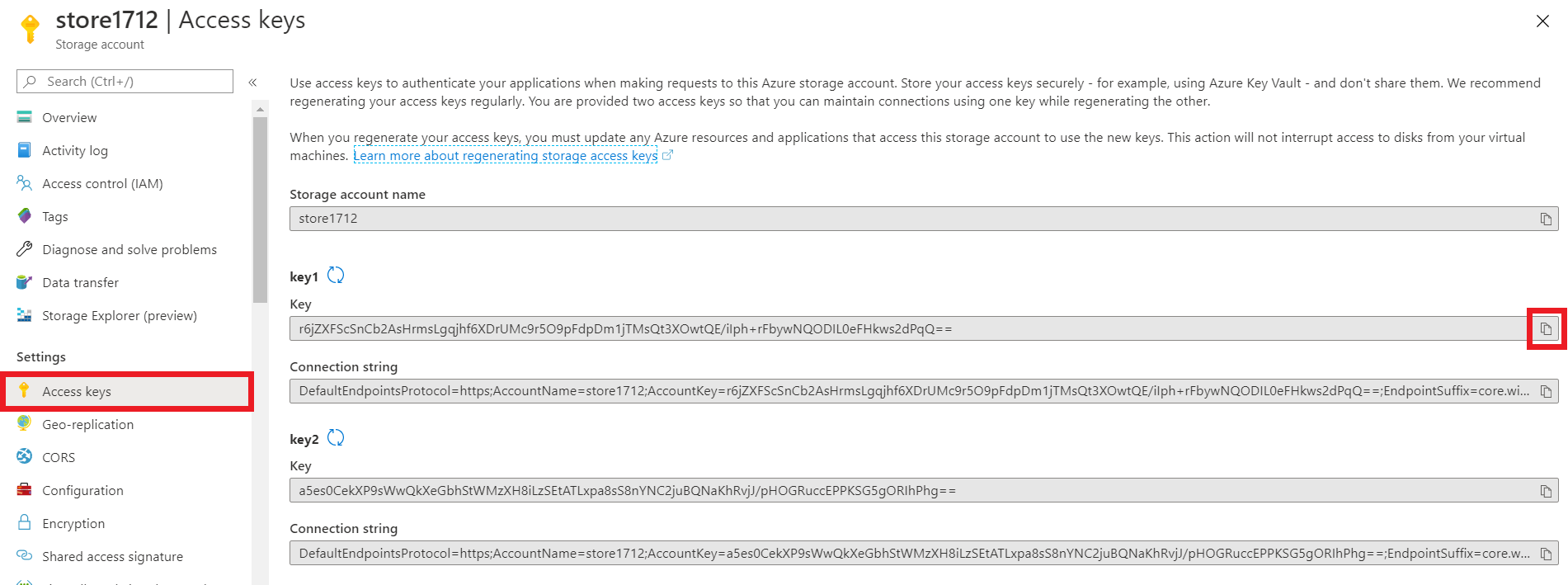
STEP 2: Create a storage account.
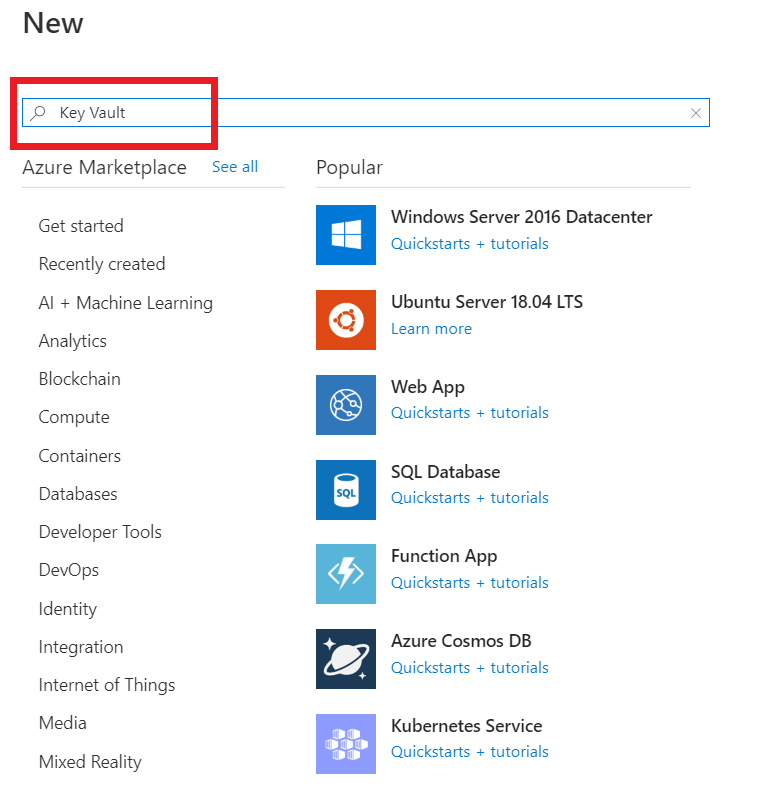
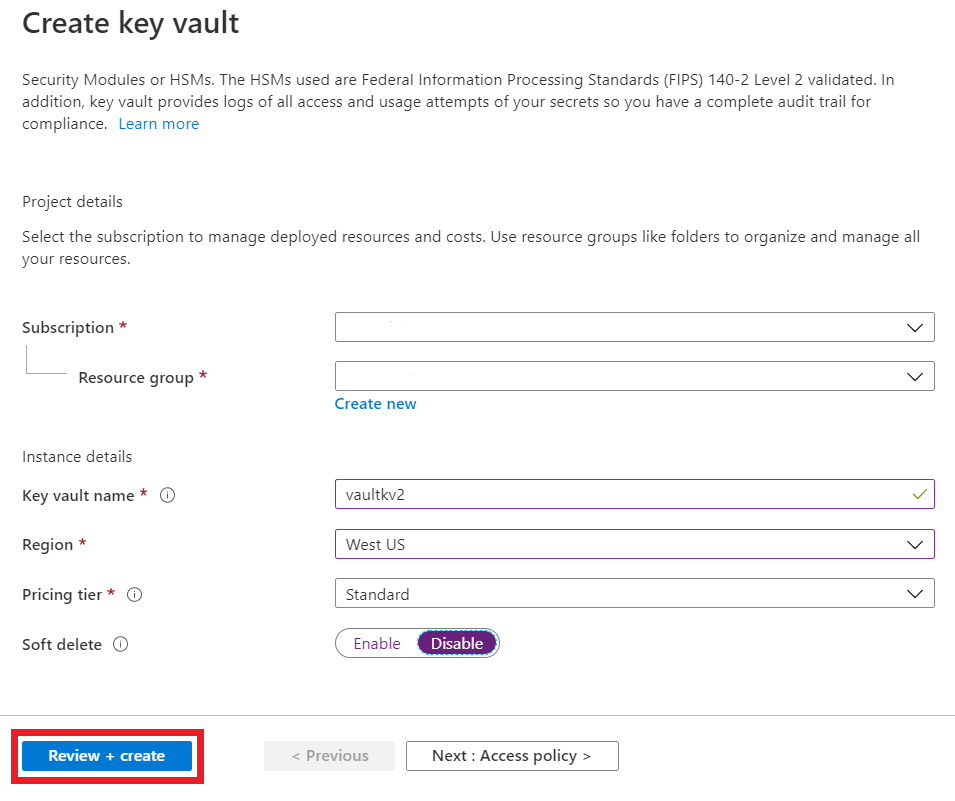
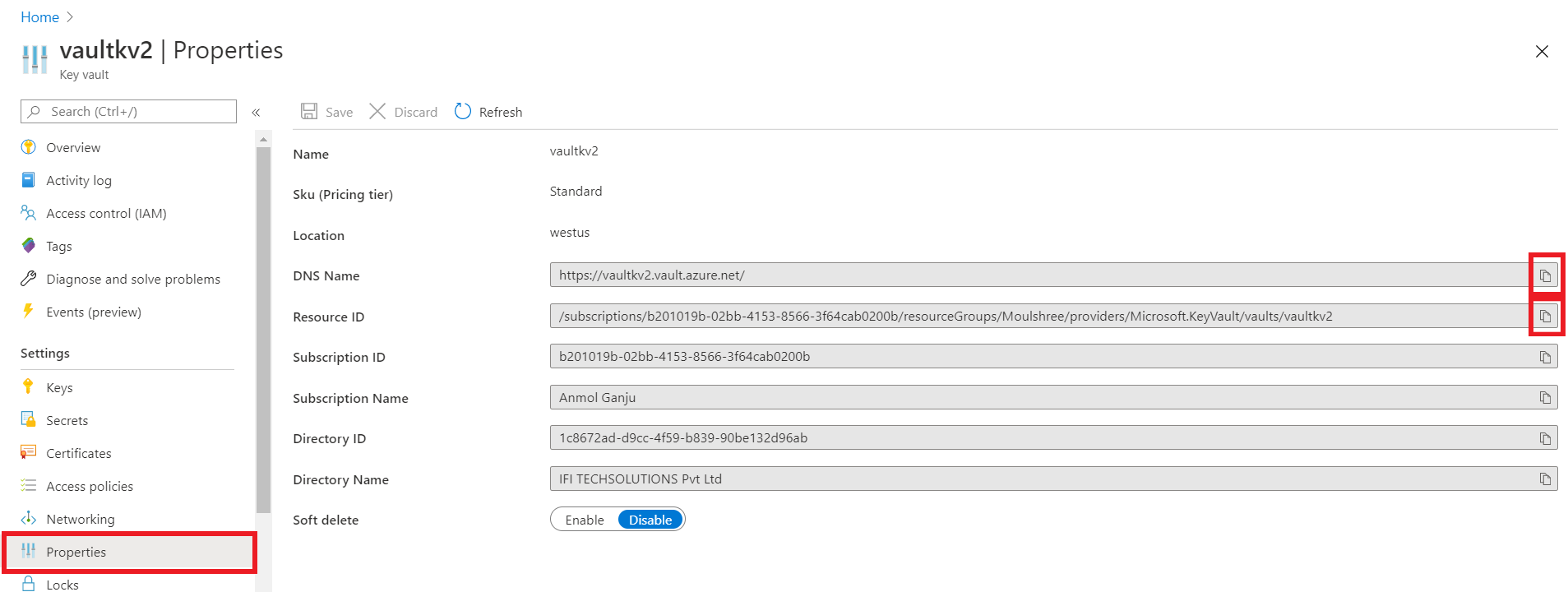
STEP 3: Create Key vault.
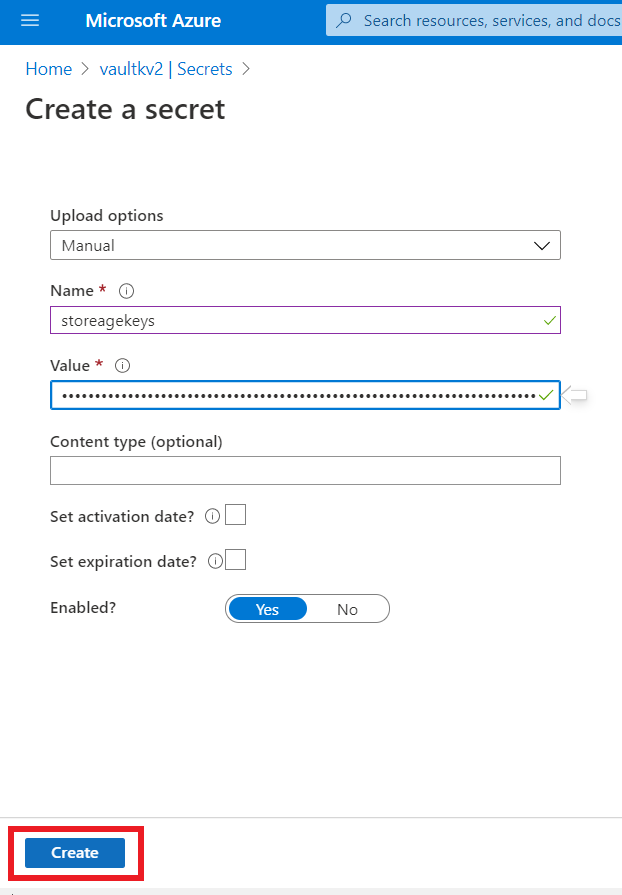
STEP 4: Create secret in Azure Key vault.
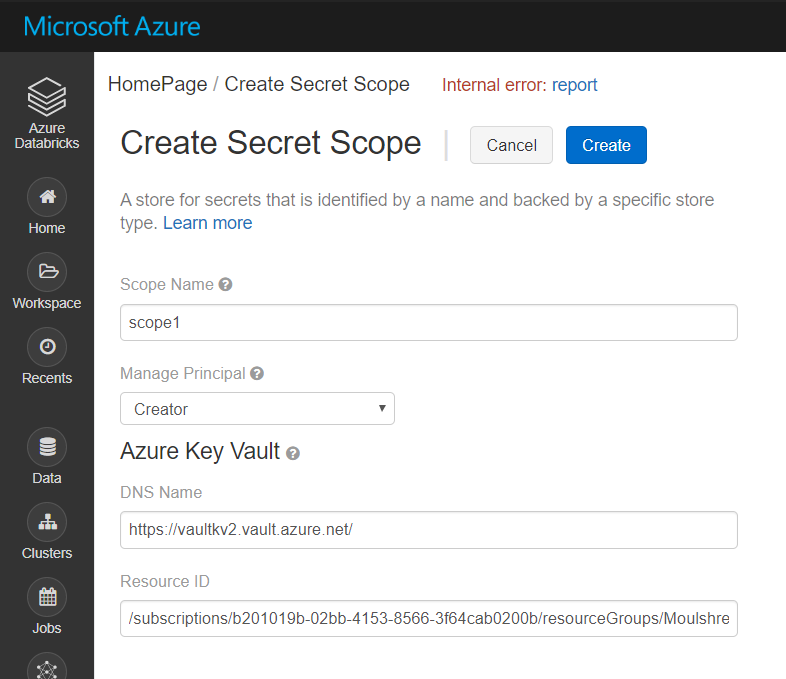
Step 5: Create Scope in Azure Databricks.
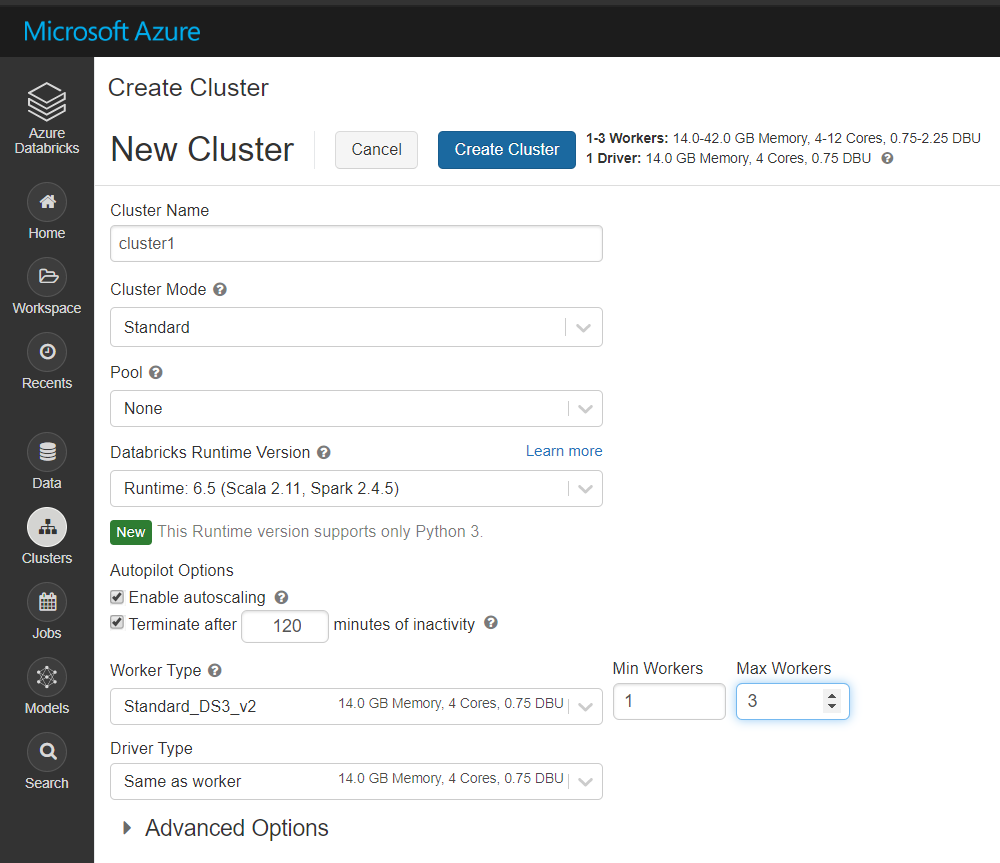
Step 6 - Create a cluster and notebook on Azure Databricks.
Step 7 – Run code.
2. Create a Data frame and display it. Data frame can be any name. Here it is Air1 as dataframe.
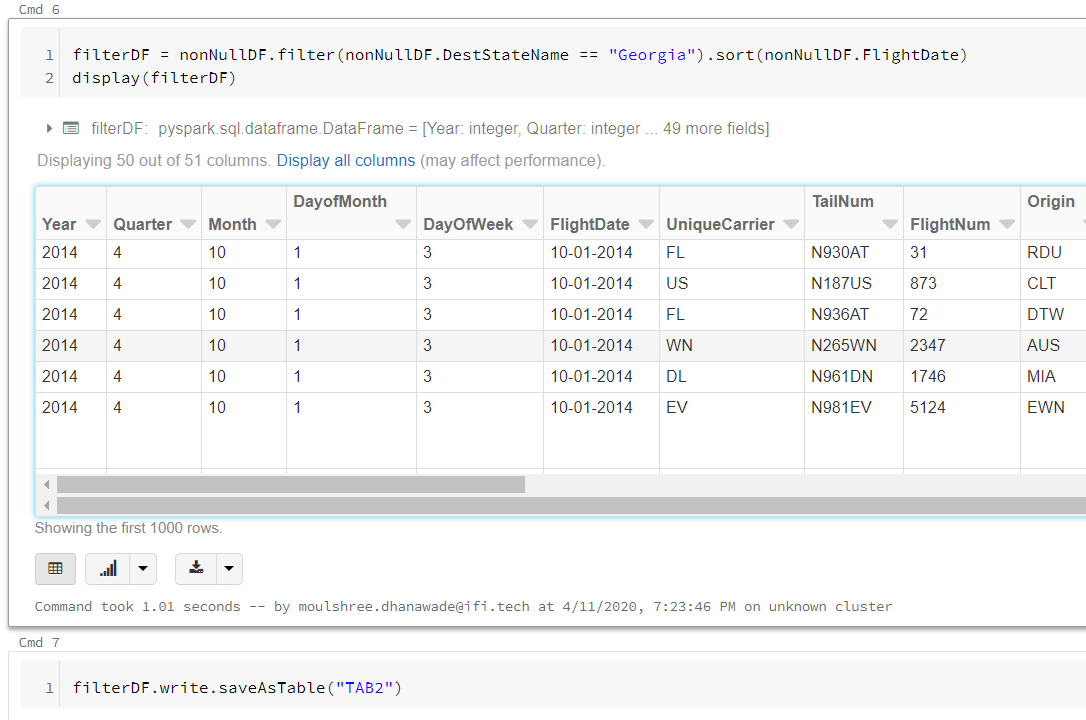
3. Apply Filter transformation and store it in a Table.
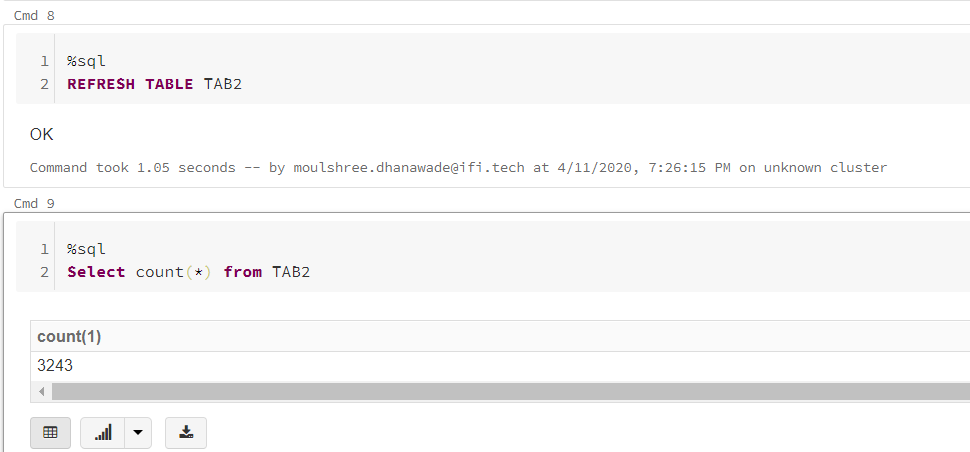
4. Refresh table and get count of rows using SQL. For running another language in the notebook, one can make use of “Magic commands”. This can be achieved by typing %language as shown below:
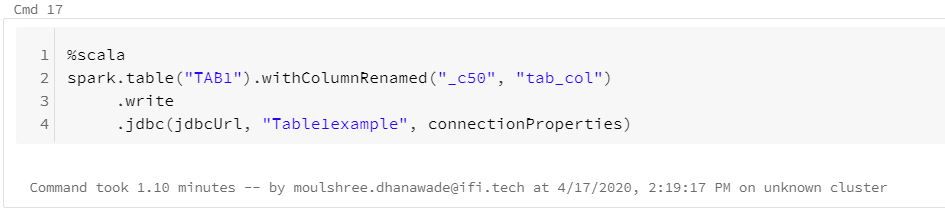
5.Write data to Azure SQL database.
6. Connect to the Azure SQL server and run command for count of rows.
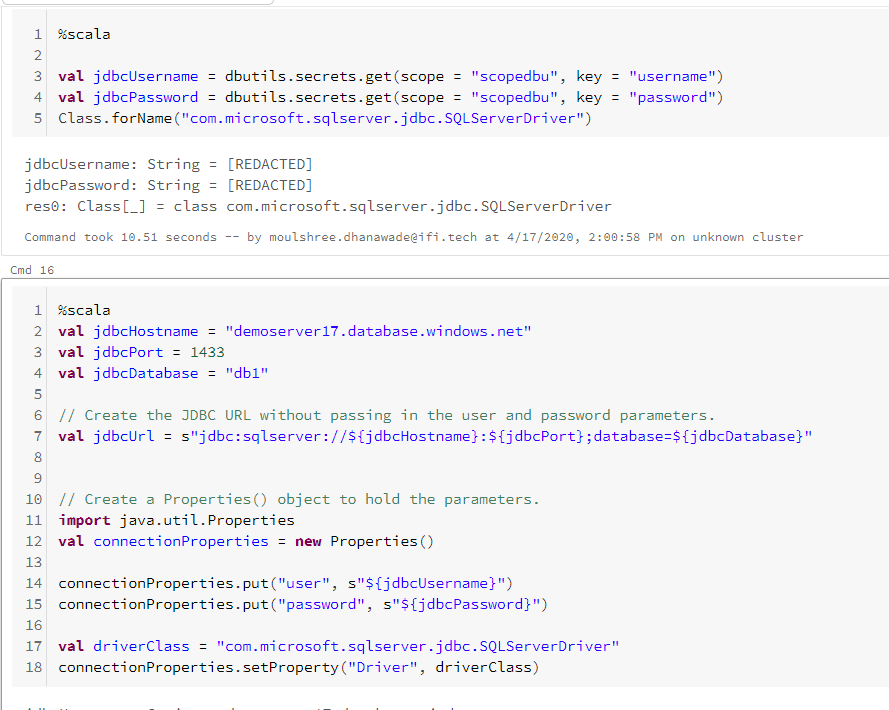
7. Setup and test the connection to Azure SQL database via JDBC.
Note: The jdbcUsername and jdbcPassword also will need to be stored in Azure key vault and a scope need to be created as shown in step 4 and step 5.
Select * from Table1example


